
파이썬 기본 문법
비전공자를 위한 프로그래밍 공부법:
전공자와 비전공자의 프로그래밍 공부법은 같을 수 없다. 전공자라면 작동법 이면의 작동원리나 다양한 문법까지 자세히 공부해야겠지만 비전공자라면 일단 빠르게 배워서 내가 원하는 분야에 제대로 사용하는 것이 우선이기 때문이다. 그래서 비전공자들을 위한 프로그래밍 공부할 때의 염두에 둬야 할 원칙 두 가지를 제시한다.
1. 먼저, 최소한으로만 공부한다.
흔히들 하는 실수가 공부를 시작할 때 의욕에 차서 두꺼운 파이썬 문법책을 첫 페이지부터 끝까지 다 공부하려 하는 것이다. 이렇게 하면 시간도 오래 걸리고 중간에 그만둘 확률이 높다. 비전공자라면 최소한의 문법만 빠르게 익히고 자신에게 필요한 프로그램을 만들면서 그때그때 필요한 것들을 공부한다는 생각으로 접근하자.
2. 구글링을 생활화하자.
프로그래밍에 있어 필요할 때 잘 찾아 쓰는 것이 실력이고 초보자는 이를 연습해야 한다. 아무리 경력이 오래된 프로그래머라 하더라도 어떤 프로그램을 만드는 데 있어서 처음부터 끝까지 자기 머리로만 만드는 사람은 절대 없다. 아무리 열심히 공부하더라도 직접 코딩하다 보면 모르거나 에러가 나는 부분이 나올 수밖에 없다. 이럴 때 당황하거나 자신의 공부가 부족해서라고 다시 처음부터 공부하기보다는 인터넷에서 검색해서 해결하는 습관을 기르자. 이렇게 일단 활용하고 자주 사용하게 되어 정말 깊은 지식이 필요할 때 제대로 공부하는 방식이 훨씬 효율적이다.
0. 파이썬 기본 데이터 형
파이썬을 비롯한 모든 프로그래밍은 기본적으로 데이터를 가지고 연산을 하는 것이다. 파이썬에는 세 가지 기본 데이터 타입이 있다. 정수와 실수, 문자열이다. 다음 그림을 보면 내용상 똑같은 3이지만 파이썬은 서로 다른 데이터로 본다. 파이썬은 위에서부터 차례로 정수, 실수, 문자열 데이터로 구분해서 인식한다.

초보일 때는 일단 숫자와 문자 데이터만 엄밀히 구분할 수 있으면 된다. 즉 str인지 아닌지만 확실하게 확인하면 된다. 정수나 실수는 함께 연산하더라도 문제가 생기지 않지만 숫자와 문자는 기본적으로 함께 연산이 되지 않기 때문이다.
정수와 실수는 덧셈뿐만 아니라 곱셈, 뺄셈, 나눗셈에서도 우리가 평소에 알고 있던 계산 결과가 나온다. 하지만 문자와 숫자를 더하면 타입 에러가 발생한다.
숫자형 데이터는 앞에서 언급한 것과 같이 상대적으로 다루기 쉽다. 우리가 평소에 알던 것과 똑같이 작동하기 때문이다. 하지만 문자열 데이터는 다소 다르므로 여기서 조금 더 살펴보자. 먼저 파이썬에서 문자열 데이터는 작음따옴표(' ')나 큰따옴표(" ")로 감싸 만든다. 이 안에 들어가면 글자든 숫자든 문자열 데이터로 인식하는 것이다. 문자열끼리는 덧셈 연산이 가능하다. 예를 들어, "안녕"이라는 문자와 "하세요"라는 문자를 더하면 "안녕하세요"가 된다. 문자열과 숫자는 유일하게 곱셈 연산이 가능한데 이는 해당 문자열을 숫자만큼 반복시킨다.
1. 변수
지금까지 파이썬의 기본 데이터를 이용해 간단한 연산을 해봤다. 프로그램은 결국 데이터를 연산하고, 그 결과를 저장한 다음 다시 연산하는 과정의 연속이다. 복잡한 프로그램은 이런 과정이 수없이 중첩돼 있는 것이다. 그렇다면 이제 데이터를 단순히 한 번 연산하는 것을 넘어 그것을 저장하고 재활용하는 방법을 배워야 한다. 이렇게 데이터에 이름을 붙여 저장하는 것을 프로그래밍에서는 '변수'라 부른다. 파이썬에서는 왼쪽에 변수 이름을 쓰고 '='을 이용해 오른쪽에 저장할 데이터를 적어주면 오른쪽에 있는 데이터가 왼쪽의 변수에 저장된다.
이렇게 새롭게 변수명을 쓰고 데이터를 저장하는 것을 변수를 선언하고 데이터(값)을 할당한다고 한다. 변수에 데이터를 할당했으면 해당 변수를 그 데이터인 것처럼 사용하면 된다.
변수명은 자유롭게 만들 수 있지만 따라야 할 규칙이 있다. 여기서 초보자들이 자주 하는 실수들 몇 가지 들어 보겠다. 먼저 숫자로 시작할 수는 없다. 따라서 1test, 2test 같은 변수명은 만들 수 없다. 번호를 주고 싶다면 test1, test2처럼 끝에 숫자를 준다. 변수명의 맨 앞만 아니면 자유롭게 숫자를 변수명에 넣을 수 있기 때문이다. 그리고 변수명은 띄어쓰기를 포함하지 않는다. 만약 띄어쓰기 같은 효과를 주고 싶다면 밑줄 ('_')을 사용하자.
2. 리스트, 딕셔너리
코드를 작성하다 보면 지금과 같이 하나의 데이터를 하나의 변수명으로 관리하는 것을 넘어 여러 개의 데이터를 한 번에 관리하는 방법이 필요해진다. 이렇게 여러 개의 데이터를 한 번에 효율적으로 관리하는 것을 자료구조라 하는데 파이썬에는 4개의 기본 자료구조 타입이 있다. 리스트(list), 딕셔너리(dict), 튜플(tuple), 셋(set)인데 여기서는 가장 중요하고 많이 쓰이는 리스트와 딕셔너리만 살펴보겠다.
먼저 리스트는 대괄호([ ])로 생성하고 콤마(,)로 각 데이터를 구분한다. 다음 그림에서는 menu라는 변수에 3개의 문자열 데이터로 이뤄진 리스트를 저장했다. 리스트의 원소로는 숫자, 문자열과 같은 기본형 데이터뿐만 아니라 리스트 자체도 들어갈 수 있다. 기본적으로 원소가 될 수 있는 데이터 타입의 제한이 없다.
파이썬 리스트에서 가장 중요한 점은 '순서'가 있다는 것이다. 리스트는 저장된 데이터들 각각에 순서가 있어서 이 순서를 이용해 데이터를 관리한다. 리스트에서 데이터를 불러올 때도 이 순서를 이용해야 한다. 예를 들어 menu 리스트에서 '짜장면'이라는 문자열 데이터를 가져오고 싶다면 첫 번째 순서이므로 0번 데이터를 달라고 명령을 내려야 한다. 단순히 하나의 데이터만 불러오는 게 아니라 범위를 지정해서 여러 개의 데이터를 한 번에 가져올 수 있다. 이렇게 범위를 지정할 수 있는 것도 데이터마다 순서가 있기 때문에 가능하다. 이때는 여러 개의 데이터를 리스트 형식으로 가져온다.
딕셔너리는 리스트와 달리 데이터 사이에 순서가 없다. 대신 데이터마다 대응하는 키 값이 있어서 이를 이용해 데이터를 관리한다. 딕셔너리는 중괄호({})로 생성하고 키와 데이터를 콜론(:)으로 대응시킨다. 이러한 키, 데이터 쌍은 리스트처럼 콤마(,)로 구분한다. 순서가 없기 때문에 리스트처럼 순서를 이용해 데이터를 가지고 오지 않고 키 값을 이용해 데이터를 가지고 온다.
3. 반복문
파이썬으로 데이터를 저장하고 연산하는 방법을 배웠다면 이제 반복문과 조건문을 배울 차례다. 지금까지 데이터를 저장하고 연산해보면서 느꼈겠지만 파이썬은 위에서부터 아래로 순서대로 실행된다. 이를 하나의 흐름이라 하는데 프로그래밍하다 보면 이 흐름에 변화를 줘야 할 때가 있다. 예를 들어 특정 부분을 반복하거나 조건에 따라 어떤 부분은 실행하지 않고 지나가야 할 때가 있다. 이런 것들을 프로그래밍에서 '흐름 제어'라 하며, 대표적으로 '반복문'과 '조건문'이 그것이다.
파이썬에서 반복문은 for문과 while 문으로 두 종류가 있다. 먼저 for문부터 살펴보자. for문은 간단한 문법으로 리스트 안의 데이터를 순회하며 명령을 반복한다. 문법은 다음과 같다.
for <임시변수> in <리스트>:
반복할 명령문
정확히 말하자면 리스트 자리에 꼭 리스트만 오는 것은 아니지만 지금은 일단 이렇게만 알아두자.
for 문이 시작되면 리스트에서 데이터들을 꺼내와 임시변수에 할당한다. 이렇게 할당된 변수는 반복문 안에서 사용된다. 그리고 그 안에 있는 명령문은 리스트의 길이만큼 반복되는 것이다.
range(1, 100)은 1부터 시작해서 1씩 증가해서 99로 끝나는 리스트가 만들어진다고 생각하면 편하다. 주의할 점은 시작하는 숫자는 범위에 포함되지만 끝나는 숫자는 범위에 포함되지 않는다는 것이다.
또 다른 파이썬 반복문으로 while 문이 있다. while 문은 조건문이 참일 동안만 명령이 반복된다. 먼저 문법을 먼저 살펴보자.
while <조건문>:
반복할 명령문
while 문을 이용해 1부터 5까지 출력한다고 하면 다음 그림과 같이 코드를 작성하면 된다. while 문의 조건문을 위해 먼저 a라는 변수에 1을 할당하고 a를 출력할 때마다 a를 1씩 증가시켰다. a가 6이 되는 순간 조건문은 거짓이 되므로 반복이 끝난다.
파이썬에서 반복문을 작성할 때는 들여쓰기에 주의해야 한다. for문과 while 문 모두 콜론(:) 다음 문장은 항상 들여쓰기를 해야 한다. 스페이스바를 4번 누르거나 탭을 한 번 눌러서 들여쓰기를 해주자. 파이썬에서는 들여쓰기가 문법이라서 초보일 때 가장 혼란스러운 부분 중 하나다.
4. 조건문
조건문의 문법은 다음과 같다.
if <조건문1>:
명령문1
elif <조건문2>:
명령문2
else:
명령문3
위 예제와 같이 조건문의 첫 번째 조건은 if로 시작한다. 파이썬은 코드를 수행하다가 if를 만나면 그 옆에 있는 조건을 검사하고 참이라면 해당 조건에 딸린 명령문을 수행한다. 만약 조건이 거짓이라면 해당 명령문은 무시되고 아무 일도 발생하지 않고 지나가게 된다.
조건문에서 조건이 한 가지라면 if 문 하나만 쓰면 되지만 조건이 두 개 이상일 때는 elif 문을 함께 사용하게 된다. 이 경우 맨 위에 있는 if문부터 아래에 있는 elif 문으로 차례로 조건의 참, 거짓을 판별하다가 조건이 참이라면 해당 조건의 명령문을 수행하고 나머지 조건은 보지도 않고 전체 조건문을 마치게 된다. 마지막으로 else 문은 일종의 여집합 같은 의미로 위에 있는 조건이 모두 참이 아니라면 아래의 명령을 수행하라는 뜻이다. 즉, 위에서부터 if, elif문에 해당하는 조건들이 모두 참이 아니라면 else 문에 있는 명령문이 수행된다. 만약 else문이 없다면 조건문에서 참인 조건이 없을 때 아무것도 수행하지 않을 수도 있지만, else 문이 있다면 최소한 하나의 조건은 수행하게 된다.
마지막으로 조건문의 예를 하나 살펴보자. 다름 그림에 있는 코드는 number라는 변수에 할당된 숫자가 양수인지 음수인지, 둘 다 아니면 0인지 판별하는 코드다.

5. 함수
함수는 보는 각도에 따라 여러 의미로 설명할 수 있는데, 필자는 독자들이 '코드에 이름을 붙여주는 것'이라고 기억해 줬으면 한다. 먼저 완성된 코드에 이름을 붙여주는 것이 왜 필요한지 살펴보자. 예를 들어 부동산 데이터를 분석해서 투자할 만한 지역을 찾아주는 파이썬 코드를 만들었다고 가정해 보자. 이런 코드를 만들어 놓고 다른 프로그램을 만들다가 앞에서 만든 부동산 데이터를 분석하는 기능이 필요해졌다면 어떻게 하면 될까?
지금까지 배운 지식으로는 앞에서 만든 코드를 복사해서 필요한 곳에 붙여넣는 방법밖에 없다. 이렇게 앞에서 만든 코드를 필요하다고 해서 다른 곳에 복사해서 붙여넣으면 꼭 문제가 생기게 된다. 이전의 코드와 변수명도 다를 테고, 긴 코드를 붙여넣으면서 들여쓰기가 엉망이 되거나 코드 몇 줄을 빠트릴 위함도 있다. 만약 여러분이 먼저 만든 코드를 함수화해서 이름을 붙여 주었다면 모든 코드를 필요한 부분에 붙여넣을 필요 없이 함수의 이름만 불러주면(호출하면) 그 위치에서 코드를 실행한 효과를 얻게 된다. 그렇다면 앞에서 마주친 문제점들을 모두 피할 수 있다. 따라서 완성된 코드를 함수화하는 것은 다른 곳에서 해당 코드를 이용할 때, 즉 재사용성을 높이기 위해 꼭 필요한 작업이다.
파이썬에서 함수를 정의하는 방법은 다음과 같다. 먼저 '정의한다'는 의미로 define의 준말인 def를 쓰고 이어서 함수명을 쓴다. 그리고 함수명 뒤에는 꼭 괄호를 붙여 줘야 한다. 괄호 안에는 함수에 들어갈 인자가 있다면 인자를 써준다. 함수의 인자는 함수를 호출할 때 사용자가 전달하는 입력값이다. 그리고 함수 안에는 함수의 내용이 되는 코드가 있다. 말하자면 우리는 이 코드에 함수명이라는 이름을 붙여주고 있는 셈이다. 함수가 끝나고 함수를 호출한 곳으로 반환할 값(돌려줄 값)이 있다면 return을 이용해 반환해줘야 한다. 반환할 값이 없다면 return을 생략할 수도 있다. 이렇게 함수를 정의하고 주피터 노트북에서 함수를 정의한 코드를 실행하면 함수명과 함수에 있는 코드가 서로 매칭되어 해당 노트에서 정의한 함수를 호출해서 사용할 수 있게 된다. 주의할 점은 함수를 정의한 코드를 실행해도 아므런 결과를 볼 수 없다는 것이다. 함수를 정의한 코드는 함수명과 코드를 매칭한 것 뿐이고, 이후 함수명을 호출해서 사용해야 함수에 있는 코드가 동작하는 것이다.
def 함수명(인자들):
함수의 내용이 되는 코드
return 반환 값(들)
예제: 다음은 밑변과 높이가 주어졌을 때 빗변의 길이를 구하는 코드다. 말하자면 피타고라스의 정리를 코드로 작성한 것이다.

이를 함수로 바꿔보자. 앞서 살펴본 함수 문법에 맞춰 다음과 같이 코드를 만들면 된다. 하지만 함수를 정의하고 실행해도 아무런 일이 일어나지 않는다. 함수를 정의한 것은 파이썬에게 함수명과 아래에 있는 코드가 서로 매칭하는 것이라고 알려준 것에 지나지 않기 때문이다. 아래 그림처럼 함수를 정의했다면 함수명은 호출해 사용해 보자. 여기서 함수명을 pita라고 했으니 pita()라고 호출하면 된다. 함수 안에서는 변수명 뒤에 ft라고 붙였는데, 이는 앞서 살펴본 코드의 변수명들과 구별하기 위해서다.

위 코드는 hypotenuse_ft 변수를 반환했다. 그래야 pita 함수를 호출한 결과가 출력되는 모습을 볼 수 있다.
이렇게 코드를 함수로 만드니 완벽해 보이지만, 아직 개선할 곳이 한 군데 더 남아있다. 위 함수는 항상 높이가 3이고 밑변이 4인 삼각형의 빗변 길이만을 구한다. 만약 높이가 2이고 밑변의 길이가 3인 삼각형의 빗변 길이를 구하려면 함수 안의 코두를 고쳐야 한다. 이렇게 한 번 완성된 함수를 필요할 때마다 새로 재정의해서 사용하는 것은 효율적이지 않다. 이렇게 자주 바뀌는 부분은 사용자가 함수를 호출할 때 입력값으로 전달할 수 있게 만들면 훨씬 효율적일 것이다.

6. 판다스의 시리즈(Series)
파이썬이 오늘날 독보적인 인기를 차지하게 된 이유 중 하나는 수많은 모듈이 있기 때문이다. 판다스(Pandas)도 파이썬 모듈 중 하나인데 데이터 분석을 더 편하고 효율적으로 수행하기 위해 만들어진 데이터 분석 모듈이다. 먼저 다음 그림과 같이 모듈을 임포트(import)해보자. 특정 모듈을 지금 코딩하는 주피터 노트북 등에서 사용하려면 이처럼 임포트해서 가져와야만 사용할 수 있다. 아래 그림을 보면 'import pandas'라고 한 뒤 'as pd'라는 구절을 덧붙여 주었는데 이는 모듈의 별명을 붙여 주는 것으로 이런 방식으로 모듈을 임포트하면 현재 노트 페이지에서는 판다스를 pd라는 별명으로 사용할 수 있다. 보통 데이터 분석에서 판다스를 pd라고 흔히 줄여 부르는데, 여기서도 그런 관습을 따라 pd라고 별명을 붙여 주었다.
판다스는 시리즈(Series)와 데이터프레임(Dataframe)이라는 새로운 자료구조를 사용자에게 제공한다. 이 자료구조는 기존의 파이썬 기본 자료구조보다 훨씬 강력한 성능을 가지고 사용자가 데이터 분석을 쉽고 효율적으로 할 수 있게 도와준다. 따라서 파이썬을 이용해 데이터 분석을 하려면 판다스가 제공하는 시리즈와 데이터프레임을 잘 알아둘 필요가 있다. 여기서는 시리즈와 데이터프레임이 각각 무엇인지 살펴보고 기본적인 기능만 짚고 넘어가겠다.
먼저 시리즈(Series)는 파이썬의 리스트와 유사한 자료구조다. 1차원 자료구조이고 데이터끼리 순서가 있다. 여기서 1차원이라는 것은 일단 리스트처럼 데이터가 한 줄로 저장되는 것이라고만 생각하자. 구체적인 예를 보면 이해하기가 더 쉬울 것이다. 다음 코드를 보자.
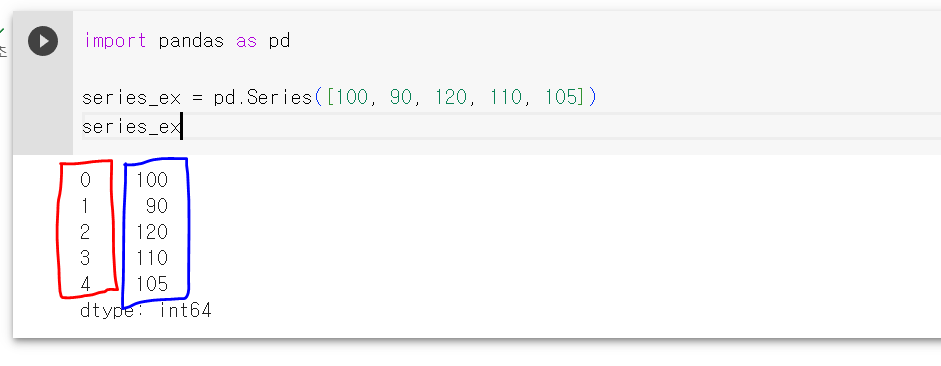
위 코드는 [100. 90, 120, 110, 105] 리스트를 이용해 시리즈 하나를 생성하는 코드다. 판다스의 Series 함수를 이용해 입력값으로 리스트를 전달하면 자동으로 시리즈 하나가 생성된다.
생선된 결과를 보면 두 부분으로 나뉘는데 인덱스와 값이다.
먼저 값을 살펴보면 리스트로 전달한 값의 순서가 보존된 채로 시리즈를 형성하고 있음을 알 수 있다. 앞에서 말한 대로 시리즈는 리스트처럼 순서가 있기 때문이다. 인덱스는 딕셔너리의 키처럼 각 값들의 이름이라 할 수 있는데 여기서 인덱스 값을 따로 주지 않자 판다스가 알아서 0, 1, 2와 같은 숫자를 부여했다. 인덱스를 설정해서 다시 시리즈를 만들어 보자.

Series 함수를 사용할 때 값이 될 리스트 외에도 index를 옵션으로 전달하면 위 그림과 같이 해당 값을 시리즈의 인덱스로 설정해준다. 주의해야 할 점은 이렇게 인덱스를 설정할 때 값의 길이와 인덱스의 길이가 같아야 한다는 것이다. 위에서 값이 될 리스트 안에 데이터가 5개 들어있기 때문에 인덱스도 5개이고, 각 값이 순서대로 매칭됐다.
이렇게 생성된 시리즈에서 데이터를 선택하고 싶으면 해당 데이터의 인덱스를 이용하면 된다.
시리스는 리스트처럼 순서가 있다. 따라서 인데스명을 이용해 데이터를 선댁할 수도 있지만, 리스트처럼 순서를 이용해 데이터를 선택할 수도 있다.
정리해 보면 시리즈는 '데이터 값'과 '인덱스'로 이뤄진 자료구조다. 재미있는 것은 시리즈는 데이터끼리 순서도 있지만 각 데이터의 이름인 인덱스도 있다는 것이다. 마치 파이썬의 리스트와 딕셔너리의 장점만 모아 놓은 자료구조라 할 수 있다.
7. 판다스의 데이터프레임 (Data Frame)
판다스의 데이터프레임(Dataframe)은 2차원의 자료구조다. 앞에서 시리즈가 1차원 데이터 구조라고 했는데, 데이터프레임은 시리즈보다 축이 하나 더 추가되는 셈이다. 시리즈는 인덱스와 데이터 값으로 구성된다고 했는데, 데이터프레임은 인덱스와 데이터 값에 추가로 '칼럼'이라는 요소가 하나 더 존재한다. 일반적으로 인덱스는 데이터프레임의 행을 대표하는 이름이고 칼럼은 열을 대표하는 이름을 뜻한다. 데이터프레임도 구체적인 예를 살펴보자.
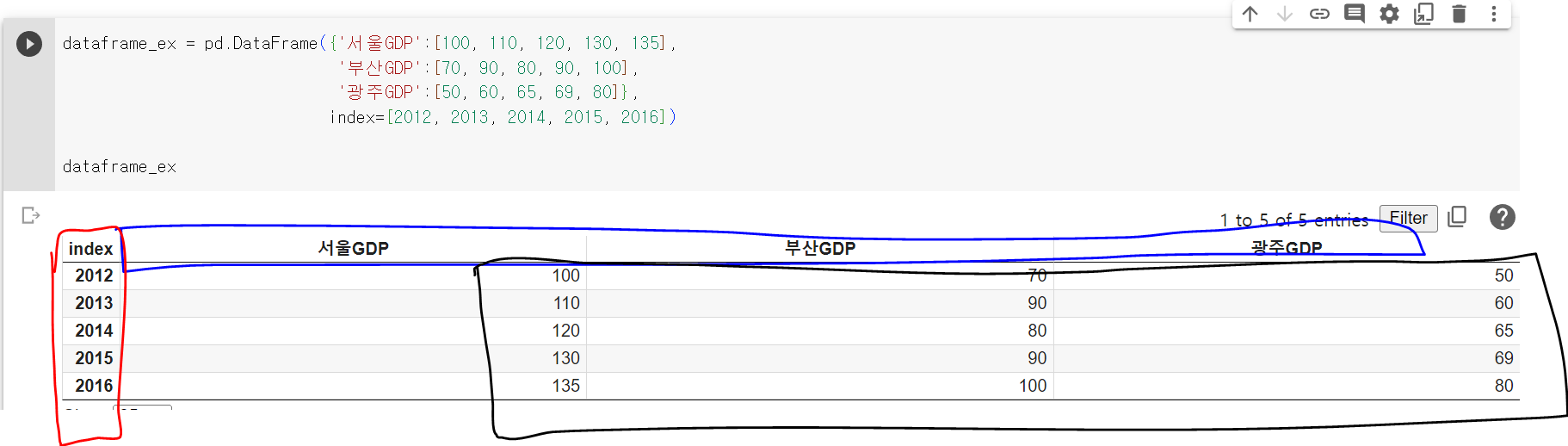
데이터프레임은 판다스의 DataFrame 함수를 이용해 생성할 수 있다. 앞의 시리즈는 1차원이기 때문에 리스트 하나가 들어갔지만 데이터프레임은 여러 개가 들어가는 것을 알 수 있다. 주의할 점은 리스트 여러 개가 딕셔너리 형태로 들어간다는 것인데, 이는 각 리스트마다 키 값으로 리스트의 이름을 함께 전달해야 하기 때문이다. 위 그림에서 첫 번째 리스트는 킷 값으로 '서울 GDP'가 매칭됐다. 이렇게 각 리스트에 대응되는 키 값이 데이터프레임에서 칼럼으로 설정된다. 데이터프레임을 생성할 때 인덱스는 시리즈를 생성할 때처럼 옵션으로 전달한다. 만약 여기서 인덱스를 따로 설정하지 않는다면 0, 1, 2와 같이 자동으로 숫자로 설정된다. 위 그림에서 보듯이 데이터프레임은 테이블 형태로 행과 열의 2차원으로 이루어진 데이터구조다. 이렇게 칼럼, 인덱스, 데이터가 데이터프레임의 3요소다.
이제 여기서 하나의 칼럼을 골라보자. 데이터프레임에서 하나의 칼럼을 고르는 방법은 딕셔너리에서 키 값으로 데이터를 가져온 것처럼 "데이터프레임['칼럼명']"으로 가져온다. 이렇게 명령을 실행하면 해당 칼럼 한 줄이 선택된다. 데이터프레임에서 칼럼 한 줄이 선택되면 이는 앞에서 본 시리즈 자료구조가 된다. 데이터프레임은 결국 여러 시리즈가 모여서 이뤄진 데이터 구조다.
행을 기준으로 한 줄을 가져오려면 loc이라는 명령을 이용한다. 마찬가지로 시리즈가 된다.
8. 판다스의 기본 기능
판다스의 시리즈와 데이터프레임은 데이터 분석을 위한 여러 기능이 있다. 사실상 여러분이 필요로 하는 거의 모든 기능을 가지고 있다고 해도 과언이 아니다. 따라서 판다스의 기능을 일일이 열거하며 공부하는 방법은 효과적이지 않다. 그보다 자주 쓰는 기능을 먼저 익히고 필요할 때마다 검색해서 사용하자. 여기서는 가장 많이 사용하는 기능인 '정렬'과 '필터링'만 소개하겠다.
먼저 시리즈와 데이터프레임은 모두 sort_values라는 함수를 이용해 데이터를 정렬한다. 시리즈의 정렬부터 살펴보자. 아래 코드를 보면 앞에서 만든 series_ex2 시리즈에 sort_values를 이용해 정렬했더니 데이터 값을 기준으로 정렬된 모습이다. 따라서 인덱스도 데이터와 함께 움직여 'Mon, Tue, Wed, Thur, Fri' 가 아닌 'Tue, Mon, Fri, Thur, Wed' 순이다.

sort_values는 데이터 값을 기준으로 오름차순 정렬한다. 만약 내림차순으로 정렬하고 싶다면 ascending=False라는 옵션을 따로 설정해야 한다.

이번에는 데이터프레임을 정렬해 보자.
데이터프레임 역시 시리즈처럼 sort_values 함수를 이용하면 되는데 시리즈와 다르게 기준이 되는 칼럼(혹은 인덱스)을 입력해야 한다. 다음 코드를 살펴보자.
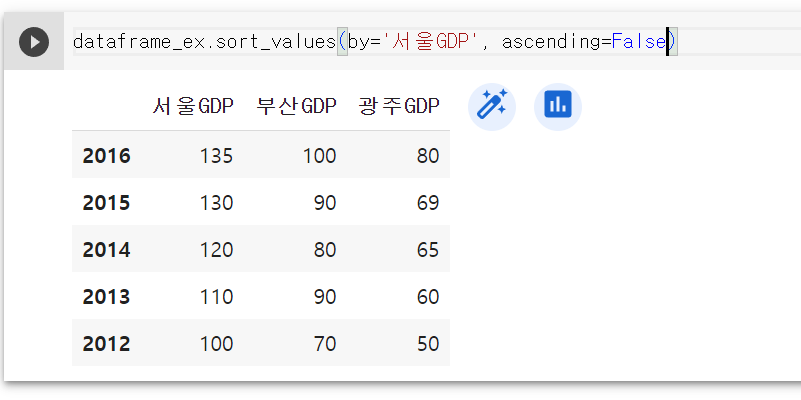
위 코드를 보면 sort_values에 by 옵션을 볼 수 있다. 데이터프레임을 정렬할 때는 by옵션을 이용해 어떤 칼럼을 기준으로 정렬할 것인지 꼭 명시해야 한다. 위의 예는 '서울GDP' 칼럼을 기준으로 정렬한 것이다. 서울GDP 칼럼을 기준으로 내림차순 정렬을 하니 인덱스의 순서가 2016, 2015, 2014, 2013, 2012가 됐는데, 다른 칼럼도 모두 이 인덱스 순서로 데이터가 정렬된다.
이제는 필터링을 살펴보자. 시리즈는 데이터를 선택하려면 괄호([ ])를 이용해 인덱스명을 입력했고, 데이터프레임은 칼럼명, 인덱스명을 이어서 입력했다. 괄호 안에는 이렇게 인덱스나 칼럼명만 넣을 수 있는 것이 아니라 조건식도 넣을 수 있다. 그러면 시리즈와 데이터프레임은 그 조건식에 맞는 데이터만 찾아온다. 시리즈의 예부터 살펴보자.
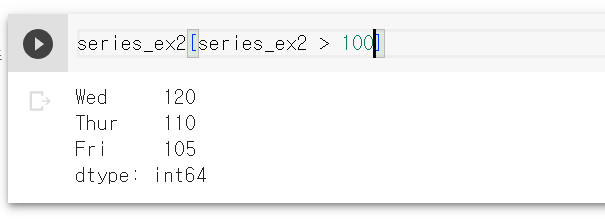
결과는 보는 것과 같이 100보다 큰 값인 Wed, Thur, Fri 데이터가 나왔다. 100보다 작은 값인 Mon, Tue는 빠진 시리즈다.
데이터프레임을 필터링하는 방법도 마찬가지다. 예를 들어 '부산 GDP'가 80보다 큰 연도의 데이터만 가져와 보자.
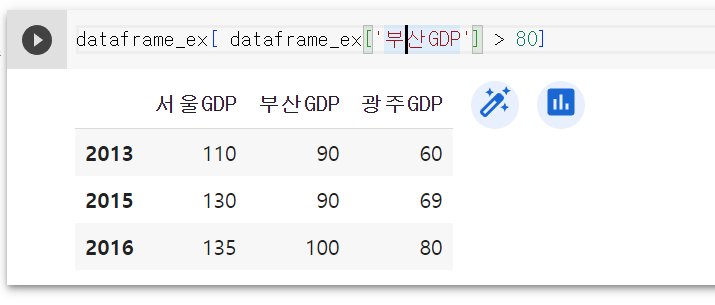
9. 주석 달기
파이썬으로 코드를 작성하다 보면 설명을 달거나 표시를 해주고 싶을 때가 있다. 이때 필요한 것이 바로 주석이다. 주석은 파이썬 코드를 실행했을 때 프로그램에 어떠한 영향도 주지 않는 글들을 뜻한다. 파이썬에서는 '한 줄 주석'과 '블록 주석'이라는 두 가지 방법으로 주석을 달 수 있다. 이 책에서는 한 줄 주석만 사용하므로 여기서는 한 줄 주석만 짚어보겠다.
